Find the best retrieval strategy for your RAG
Why this exists
Section titled “Why this exists”RAG quality lives or dies by the retrieval step. Most teams pick a retrieval pipeline by feel, by averaged leaderboard scores, or by what is already in the stack. None of those tell you how each strategy performs on your data, so the surprises show up in production.
The cure is straightforward to describe and historically painful to run: define a representative benchmark, evaluate every reasonable retrieval strategy on it, and pick by a single metric. The painful part has always been infrastructure. Most teams give up after wiring two or three different model serving stacks.
This example shows what that workflow looks like when one inference cluster can serve every retrieval, reranking, and multi-vector model the experiment needs. The result is the recipe below, the methodology that produced it, and the numbers that ruled out every alternative.
What we tested
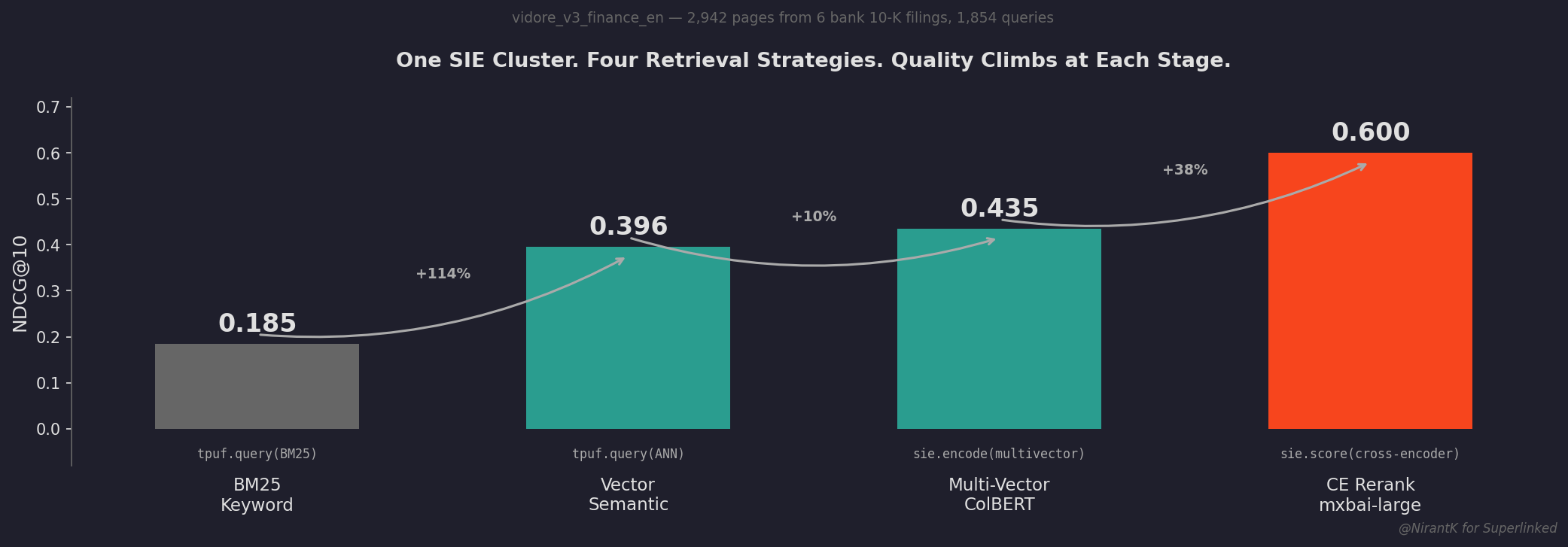
Section titled “What we tested”Six bank 10-K filings from SEC EDGAR, 1,854 real questions, 2,942 pages, eight retrieval strategies, ranked by NDCG@10.
The winner
Section titled “The winner”Dual multi-vector retrieval, then cross-encoder rerank.
- Encode queries and pages with two complementary multi-vector models,
BAAI/bge-m3(1024d) andjinaai/jina-colbert-v2(128d). - Rerank the union of both candidate pools with
mixedbread-ai/mxbai-rerank-large-v2.
On the same 1,854 queries this pipeline reaches NDCG@10 = 0.621 and Recall@10 = 0.665, 57% better than a single dense model and 3x better than BM25 alone.
Built by @NirantK for Superlinked.
Pipeline in code
Section titled “Pipeline in code”from sie_sdk import SIEAsyncClient
async with SIEAsyncClient("http://your-sie-endpoint:8080", api_key="SL-...") as sie: # Multi-vector encode with two complementary models mv_bge = await sie.encode("BAAI/bge-m3", [{"text": "quarterly revenue"}], output_types=["multivector"])
mv_jina = await sie.encode("jinaai/jina-colbert-v2", [{"text": "quarterly revenue"}], output_types=["multivector"])
# Union the two pools, rerank with a cross-encoder result = await sie.score("mixedbread-ai/mxbai-rerank-large-v2", query={"text": "quarterly revenue"}, items=[{"text": "Revenue was $50B..."}, {"text": "The board met on Tuesday..."}])Three model families, one endpoint, no container orchestration.
Run the full pipeline
Section titled “Run the full pipeline”uv sync
# Validate config (no GPU needed)uv run python benchmark_ablation.py --dry-run
# Full benchmark across all 7 models and all 1,854 queriesuv run python benchmark_ablation.py --gpu l4-spotAll expensive operations (encoding, search) cache to cache/ablation/. Re-runs skip completed steps. Cross-encoder reranking checkpoints every 100 queries for crash recovery.
How the experiment was set up
Section titled “How the experiment was set up”Dataset
Section titled “Dataset”vidore_v3_finance_en: six bank 10-K filings from SEC EDGAR.
| Property | Value |
|---|---|
| Pages | 2,942 |
| Queries | 1,854 |
| Relevance judgments | 8,766 (1=relevant, 2=highly relevant) |
| Avg relevant docs per query | 4.7 |
| Median page text | 3,809 chars (~950 tokens) |
Conditions
Section titled “Conditions”Six conditions isolate the contribution of each pipeline stage. Conditions 4 and 5 rerank the same hybrid pool, only the reranker changes. bge-m3 plays three different roles to isolate representation type from retrieval strategy.
| # | Condition | Retriever | Reranker | What it isolates |
|---|---|---|---|---|
| 1 | BM25-only | Turbopuffer FTS | none | Keyword baseline |
| 2 | Vector-only | bge-m3 dense ANN | none | Semantic baseline |
| 3 | RRF | Fused (k=60) | none | Does hybrid beat vector? |
| 4 | CE rerank | Hybrid pool | mxbai-rerank, bge-reranker | Cross-encoder value |
| 5 | MV rerank | Hybrid pool | 5 ColBERT models | MV vs cross-encoder |
| 6 | MV direct | Brute-force MaxSim | 5 ColBERT models | MV as standalone retriever |
Metrics: NDCG@10, MRR@10, Recall@10. All computed against the official qrels.
Headline results
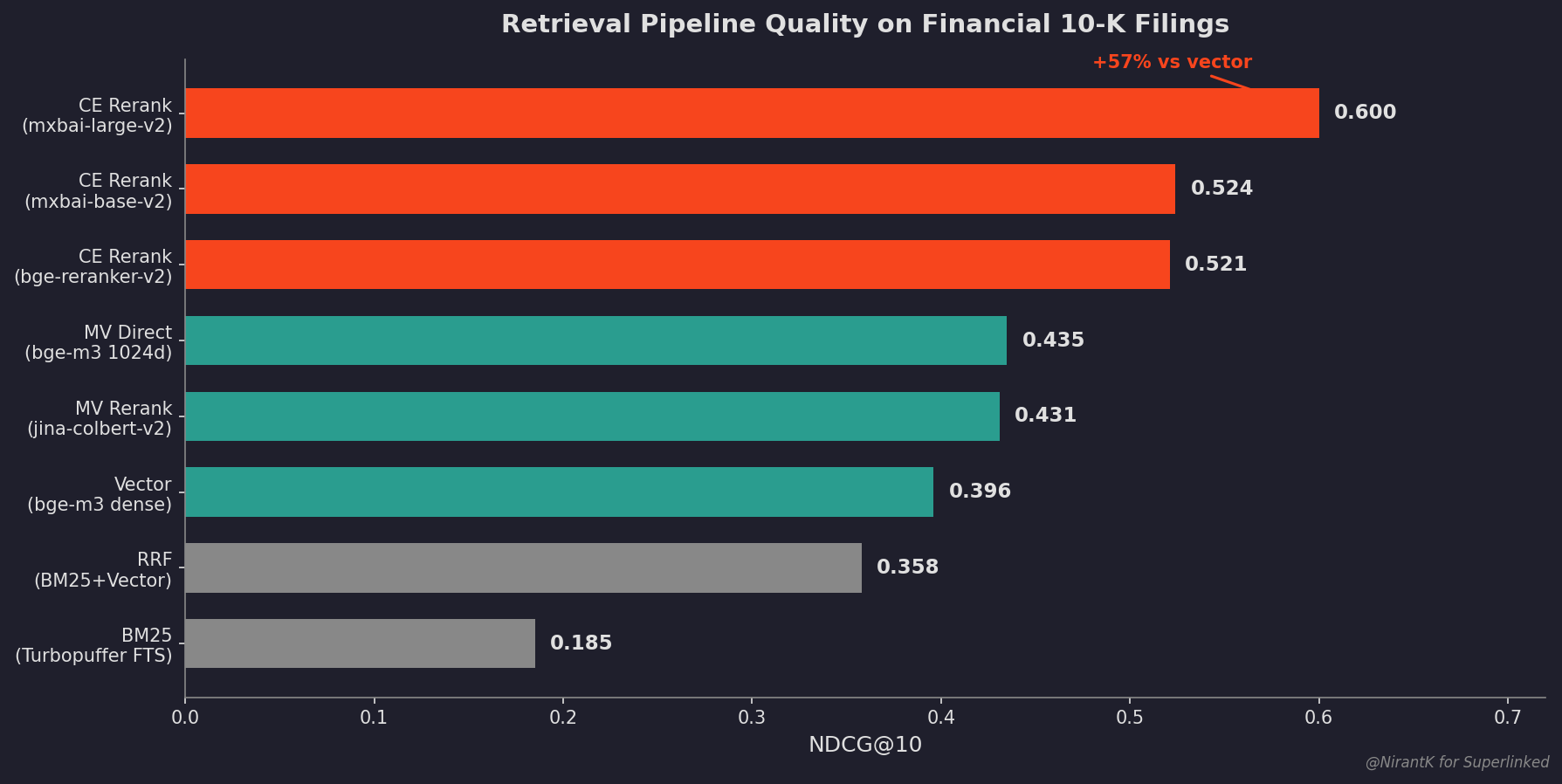
Section titled “Headline results”Ranked by NDCG@10. Larger candidate pools (TOP_K=50) consistently improved CE reranking.
| Strategy | Models | NDCG@10 | Recall@10 |
|---|---|---|---|
| Dual-MV pool, then CE rerank | bge-m3 + jina-colbert, then mxbai-large | 0.621 | 0.665 |
| MV-bge200 pool, then CE rerank | bge-m3 MV pool, then mxbai-large | 0.613 | 0.656 |
| CE rerank | mxbai-rerank-large alone | 0.600 | 0.640 |
| MV direct | bge-m3 (1024d) | 0.435 | 0.482 |
| MV rerank | jina-colbert-v2 (128d) | 0.431 | 0.494 |
| Vector | bge-m3 dense | 0.396 | 0.438 |
| RRF (BM25 + Vector) | n/a | 0.358 | 0.434 |
| BM25 | Turbopuffer FTS | 0.185 | 0.239 |
The full 15-row primary ablation, the reranker sweep, and the pool-composition experiments live in RESULTS.md.
What the numbers say
Section titled “What the numbers say”- Cross-encoder reranking wins: mxbai-large with the dual-MV pool (0.621) beats every retriever-only setup. The CE step is a bigger lever than picking a different retriever.
- Pool recall is the real bottleneck: CE scores 0.69 within-pool. The dual-MV pool reaches 0.92 recall and tops the table; a hybrid-50 pool gets 0.77 recall and trails.
- Two MV models beat one: combining bge-m3 and jina-colbert-v2 pools beats either alone. Model diversity adds recall.
- jina-colbert-v2 is the cost / quality sweet spot: 96% of bge-m3 MV quality at 12.5% storage (128d vs 1024d).
- RRF hurts on this dataset: BM25 dilutes the strong vector signal. The hybrid-fusion baseline scores worse than vector alone.
Recipes by constraint
Section titled “Recipes by constraint”- Best quality: dual MV pool, then mxbai-rerank-large CE rerank (NDCG=0.621).
- No GPU at inference: MV direct with bge-m3 (NDCG=0.435). Pre-encode offline, score with MaxSim on CPU.
- Best cost / quality: jina-colbert-v2 multi-vector (NDCG=0.431). 8x less storage than bge-m3 MV at near-identical quality.
API keys required
Section titled “API keys required”| Service | What for | Get one at |
|---|---|---|
| SIE | Encoding, scoring, multi-vector | Self-hosted (deploy guide) or contact the team |
| Turbopuffer | BM25 + vector search index (free tier covers this dataset) | turbopuffer.com |
| HuggingFace | Dataset download (free, cached) | huggingface.co/settings/tokens |
Create .env in this directory:
SIE_BASE_URL=http://your-sie-endpoint:8080# Optional: only needed for managed/auth-enabled SIE clusters.SIE_API_KEY=TURBOPUFFER_API_KEY=tpuf_...By Nirant Kasliwal.